Задание 27. Информатика. ЕГЭ. Поляков-7714
- Просмотры: 179
- Изменено: 1 февраля 2025
Учёный решил провести кластеризацию некоторого множества звёзд по их расположению на карте звёздного неба. Кластер звёзд – это набор не менее чем из 30 соседних звёзд (точек) на графике. Каждая звезда обязательно принадлежит только одному из кластеров. Центр кластера, или центроид, – это одна из звёзд на графике, сумма расстояний от которой до всех остальных звёзд кластера минимальна. Расстояние между двумя точками \(A(x_1, \, y_1)\) и \(B(x_2, \, y_2)\) вычисляется по формуле:
$$
d(A, \, B) = \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2}
$$
Аномалиями назовём точки, находящиеся на расстоянии более одной условной единицы от точек кластеров. При расчётах аномалии учитывать не нужно. Даны два входных файла (файл A и файл Б). В файле A хранятся данные о звёздах двух кластеров. 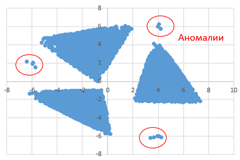 В каждой строке записана информация о расположении на карте одной звезды: сначала координата \(x\), затем координата \(y\) (в условных единицах). Известно, что количество звёзд не превышает \(1000\). В файле Б хранятся данные о звёздах трёх кластеров. Известно, что количество звёзд не превышает \(10~000\). Структура хранения информации о звездах в файле Б аналогична файлу А. Возможные данные одного из файлов иллюстрированы графиком. Для каждого файла определите координаты центра каждого кластера, затем вычислите два числа: \(P_x\) – среднее арифметическое абсцисс центров кластеров, и \(P_y\) – среднее арифметическое ординат центров кластеров. В ответе запишите четыре числа: в первой строке сначала целую часть произведения \(P_x \times 100~000\), затем целую часть произведения \(P_y \times 100~000\) для файла А, во второй строке – аналогичные данные для файла Б.
В каждой строке записана информация о расположении на карте одной звезды: сначала координата \(x\), затем координата \(y\) (в условных единицах). Известно, что количество звёзд не превышает \(1000\). В файле Б хранятся данные о звёздах трёх кластеров. Известно, что количество звёзд не превышает \(10~000\). Структура хранения информации о звездах в файле Б аналогична файлу А. Возможные данные одного из файлов иллюстрированы графиком. Для каждого файла определите координаты центра каждого кластера, затем вычислите два числа: \(P_x\) – среднее арифметическое абсцисс центров кластеров, и \(P_y\) – среднее арифметическое ординат центров кластеров. В ответе запишите четыре числа: в первой строке сначала целую часть произведения \(P_x \times 100~000\), затем целую часть произведения \(P_y \times 100~000\) для файла А, во второй строке – аналогичные данные для файла Б.
Решение:
Python
from math import dist
from turtle import *
def visualize(clusters, task):
up(); ht(); tracer(0)
k = 35
if task == 1:
colors = ('purple', 'green', 'red', 'red', 'red')
else:
colors = ('purple', 'green', 'blue', 'red', 'red', 'red', 'red', 'red')
for cl, color in zip(clusters, colors):
for p in cl:
x, y = p
goto(x * k, y * k)
dot(5, color)
exitonclick()
def get_centroids(clusters):
centroids = []
for cl in clusters:
dmin = 10**1000
for p in cl:
d = sum(dist(p, pt) for pt in cl)
if d < dmin:
dmin = d
c = p
centroids.append(c)
px = 100_000 * sum(p[0] for p in centroids) / len(centroids)
py = 100_000 * sum(p[1] for p in centroids) / len(centroids)
return int(px), int(py)
base = ''
files = ['27a.txt', '27b.txt']
for task in (1, 2):
fd = open(base + files[task-1])
fd.readline()
clusters = []
data = [[float(d) for d in line.replace(',', '.').split()] for line in fd]
#print(len(data))
while data:
clusters.append([data.pop(0)])
for point in clusters[-1]:
neighbors = [p for p in data if dist(point, p) < 1]
clusters[-1] += neighbors
for p in neighbors:
data.remove(p)
#print(len(clusters))
#print([len(x) for x in clusters])
#if task == 2:
# visualize(clusters, task)
clusters = [x for x in clusters if len(x) > 30]
#print(len(clusters))
#print([len(x) for x in clusters])
print(*get_centroids(clusters))
Ответ:
\(116343 \,\, 78978\)
\(-54692 \,\, 305054\)
Визуализация кластеров с помощью графики модуля Turtle
Файл A
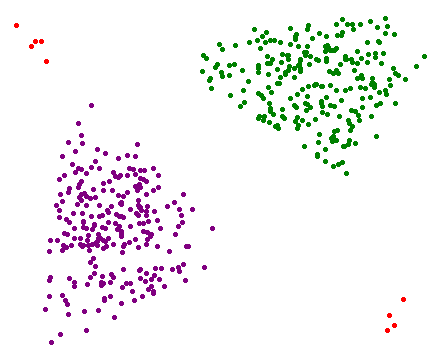
Файл B
