Задание 27. Информатика. ЕГЭ. Статград. 17.12.2024
- Просмотры: 652
- Изменено: 1 февраля 2025
В лаборатории проводится эксперимент, состоящий из множества испытаний. Результат каждого испытания представляется в виде пары чисел. Для визуализации результатов эта пара рассматривается как координаты точки на плоскости, и на чертеже отмечаются точки, соответствующие всем испытаниям.
По результатам эксперимента проводится кластеризация полученных результатов: на плоскости выделяется несколько кластеров – кругов радиуса не более \(3\) единиц так, что каждая точка попадает ровно в один кластер. Центром кластера считается та из входящих в него точек, для которой минимально максимальное из расстояний до всех остальных точек кластера. При этом расстояние вычисляется по стандартной формуле расстояния между точками на евклидовой плоскости. Радиусом кластера считается максимальное из расстояний от центра до остальных точек кластера.
Обработка результатов эксперимента включает следующие шаги:
- кластер, содержащий наименьшее число точек, исключается;
- определяются центры и радиусы всех оставшихся кластеров;
- вычисляется средний радиус оставшихся кластеров.
В файле записан протокол проведения эксперимента. Каждая строка файла содержит два числа: координаты \(X\) и \(Y\) точки, соответствующей одному испытанию. По данному протоколу надо определить средний радиус всех кластеров за исключением содержащего наименьшее число точек.
Вам даны два входных файла (A и B), каждый из которых имеет описанную выше структуру. По данным каждого из представленных файлов определите средний радиус по описанным выше правилам. В ответе запишите два числа: сначала средний радиус для файла A, затем для файла B. В качестве значения указывайте целую часть от умножения найденного числового значения на \(10~000.\)
Решение:
Python
from math import dist
from turtle import *
def visualize(clusters):
tracer(0)
up()
screensize(2500, 2500)
k = 50
color = ['red', 'green', 'blue', 'orange', 'magenta', 'black']
for cl, c in zip(clusters, color):
for p in cl:
x, y = p
goto(x * k, y * k)
dot(2, c)
ht()
update()
base = ''
files = ('27A.txt', '27B.txt')
for task in (1, 2):
clusters = []
data = []
eps = [1, 0.5]
for line in open(base + files[task - 1]):
data.append(tuple(map(float, line.replace(',', '.').split())))
while data:
clusters.append([data.pop()])
for point in clusters[-1]:
neigh = [p for p in data if dist(p, point) < eps[task - 1]]
clusters[-1] += neigh
for p in neigh:
data.remove(p)
#if task == 2:
# visualize(clusters)
ml = min(len(cl) for cl in clusters)
clusters = [cl for cl in clusters if len(cl) > ml]
centers = []
rad = []
for cl in clusters:
dmin = 10**1000
for pt in cl:
d = max(dist(pt, p) for p in cl)
if d < dmin:
dmin = d
c = pt
centers.append(c)
rad.append(max(dist(c, p) for p in cl))
print(int(10_000 * sum(rad) / len(rad)))
Ответ:
\(10001\)
\(8504\)
Визуализация кластеров с помощью графики модуля Turtle
Файл A
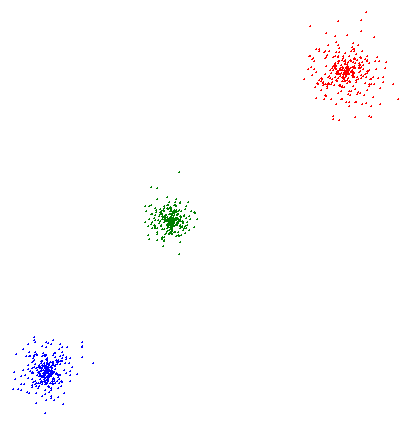
Файл B
