Задание 27. Информатика. ЕГЭ. ЕГКР. 21.12.2024
- Просмотры: 1713
- Изменено: 1 февраля 2025
Фрагмент звёздного неба спроецирован на плоскость с декартовой системой координат. Учёный решил провести кластеризацию полученных точек, являющихся изображениями звёзд, то есть разбить их множество на \(N\) непересекающихся непустых подмножеств (кластеров), таких что точки каждого подмножества лежат внутри прямоугольника со сторонами длиной \(H\) и \(W,\) причём эти прямоугольники между собой не пересекаются. Стороны прямоугольников не обязательно параллельны координатным осям. Гарантируется, что такое разбиение существует и единственно для заданных размеров прямоугольников.
Будем называть центром кластера точку этого кластера, сумма расстояний от которой до всех остальных точек кластера минимальна. Для каждого кластера гарантируется единственность его центра. Расстояние между двумя точками на плоскости \(A(x_1, \, y_1)\) и \(B(x_2, \, y_2)\) вычисляется по формуле: $$d(A, \, B) = \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2}$$
В файле А хранятся координаты точек двух кластеров, где \(H = 6, \, W = 6\) для каждого кластера. В каждой строке записана информация о расположении на карте одной точки: сначала координата \(x,\) затем координата \(y.\) Известно, что количество точек не превышает \(1000.\)
В файле Б хранятся координаты точек трёх кластеров, где \(H = 5, \, W = 5\) для каждого кластера. Известно, что количество точек не превышает \(10~000.\) Структура хранения информации в файле Б аналогична файлу А.
Для каждого файла определите координаты центра каждого кластера, затем вычислите два числа: \(P_x\) — среднее арифметическое абсцисс центров кластеров, и \(P_y\) — среднее арифметическое ординат центров кластеров. В ответе запишите четыре числа: в первой строке сначала абсолютное значение целой части произведения \(P_x \times 10~000,\) затем абсолютное значение целой части произведения \(P_y \times 10~000\) для файла А, во второй строке — аналогичные данные для файла Б.
Решение:
Python
from math import dist
from turtle import *
def visualize(clusters):
tracer(0)
up()
screensize(2500, 2500)
colors= ('red', 'green', 'blue', 'orange', 'magenta')
k = 20
for cl, c in zip(clusters, colors):
for p in cl:
x, y = p
goto(x * k, y * k)
dot(3, c)
ht()
update()
base = ''
files = ('27_A.csv', '27_B.csv')
for task in (1, 2):
fd = open(base + files[task-1])
fd.readline()
data = [tuple(map(float, line.replace(',', '.').split(';'))) for line in fd]
clusters = []
while data:
clusters.append([data.pop(0)])
for p in clusters[-1]:
neigh = [pt for pt in data if dist(p, pt) < 2]
clusters[-1] += neigh
for pt in neigh:
data.remove(pt)
#print(len(clusters))
#print([len(x) for x in clusters])
#if task == 2: visualize(clusters)
centers = []
for cl in clusters:
dmin = 10**1000
for p in cl:
d = sum(dist(p, pt) for pt in cl)
if d < dmin:
dmin = d
c = p
centers.append(c)
px = int(10_000 * sum(p[0] for p in centers) / len(centers))
py = int(10_000 * sum(p[1] for p in centers) / len(centers))
print(abs(px), abs(py))
Ответ:
\(43789 \,\, 62202\)
\(14271 \,\, 54727\)
Визуализация кластеров с помощью графики модуля Turtle
Файл A
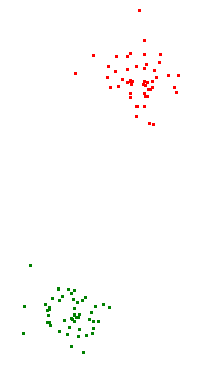
Файл B
